This is my rundown of AWS’s whitepaper about Implementing Microservices on AWS. Without further ado, let’s get started. In this article I talk more about micrsoservices and less about AWS. I also talk about paths already engraved around microservices.
While you read this post, take a moment to connect with me on LinkedIn.
What are microservices?#
Microservices are an architectural and organizational approach to software development where software is composed of small independent services that communicate over well-defined APIs. These services are owned by small, self-contained teams.
Benefits of microservices#
So with microservices, the main benefits we get are:
- We can divide developers into logical groups.
- Faster deployment cycles.
- From developer point of view, we get flexibility of choosing technologies we are familiar with.
- We can scale the application based on load horizontally which is cost effective)
- We get resiliency because if one machine goes down, there is always other machine to take over in shorter span of time, automatically.
Contrast between a monolith and a microservice#
We can contract microservices with monolith architecture. The table below shows differences between them.
| Monolith | Microservices |
|---|---|
| Application built as one unit, using different layers | Applications built as a series of individual components |
| Scaling any part of the app means scaling the entire app | Each component can scale independently. |
| As the applications change, their code bases become more complex | Changes are simpler because they’re confined to individual components |
| Teams have limited autonomy | Teams have more autonomy to make changes as they need to |
As you can see in the monolith architecture image below, we have User Interface, Account Service, Cart Service, Shipping Service, Data Access Service layers.

In microservices pattern, we get to choose hardware based on our requirements. If a service which requires more IO throughput, it will get that. If a service requires memory, it will get it. If it needs more CPU it will get it. This all happens on per service basis. In monolith, you’d have to scale everything entirely.

And if the Shipping Service team decided to change their data model, it will not affect other services in the application.
Contrast between Serverless and Microservice#
Serverless is more of an architectural term in terms of infrastructure. You don’t need to provision, configure and scale hosts on your own.
Whereas microservice design pattern can be implemented regardless of whether the machines are provisioned automatically or manually.
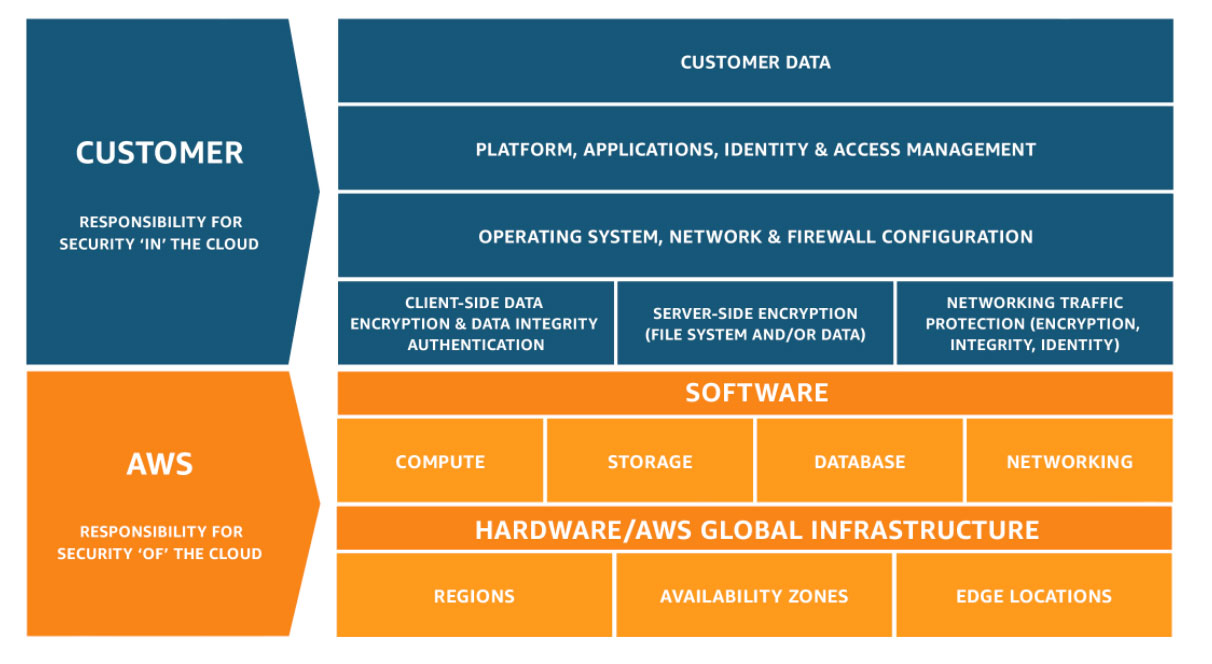
AWS Shared Responsibility Model#
While you develop your application in AWS Clould, you need to keep in mind that unlike other conventional hosting providers like PythonAnywhere / Heroku / DigitalOcean, you have more things to handle on your own. Things like networking, security groups, firewall etc, you need to configure on your own. Of course there are different levels of offering in AWS itself that provides heroku level of setup out of the box but you know what I mean.
Challenges faced while first moving to microservices#
Common challenges encountered in the early stages of microservices adoption.
- Even small code changes take too long to release. In monolith, there is only one application. Easy to track stack traces.
- Manual deployments create lack of awareness of what’s running
- Low visibility reduces time to resolution
- What works in dev environments doesn’t always work in production.
- Up-front costs may be higher with microservices.
Best practices for successful microservices adoption#
These points are important. Many businesses are not able to adopt microservices because they don’t follow a plan.
CI/CD#
- You need to bring CI/CD and DevOps practice in your application lifecycle.
- Automate your software delivery process using continuous integration and delivery (CI/CD) pipelines.
Monitoring and Observability#
Keep tract of all the components of your microservices architecture to understand if they’re performing correctly.
- Use metrics
- Measure application performance
- Logging
Security#
Implement the proper security measure across your microservices architecture.
- Code scanning/static analysis
- Runtime monitoring
- Incident response (automation and alerting)
- Everybody in the application lifecycle, from development, to building, to
testing, to deployment.
Application/Service Management#
Monitor and manage application tools to maintain a high quality of service.
- Deployment and application frameworks
- Application visualization and comprehension
- Configuration/secrets management/service discovery
Distributed Systems Components#
After looking at how AWS can solve challenges related to individual microservices, we now want to focus on cross-service challenges, such as service discovery, data consistency, asynchronous communication, and distributed monitoring and auditing.
Communication between services#
When breaking down monolith to microservices, one pattern which can be used here is the Producer-Consumer pattern, also known as the publisher subscriber pattern.
With producer-consumer pattern we can break the system into two parts, i.e. Producers, and Consumers. Consider the example below.

As you can see, in sub/pub system there are two kinds of services involved. One is the publisher service, also known as the producer which is responsible for taking request from load balancer or other downstream service and then convert it into a task. This task goes to a queue which which accumulates all tasks.
Next, there are certain number of workers which can subscribed to the queue. You’d pick a task from the queue, work on it, and then delete that task from the queue so that no task is done twice.
One benefit we get here is that we can scale (add or remote instances) workers and consumers separately. With monolith, we’d have to scale vertically.

Note that there are different kind of queues, routing, exchanges etc which will take another post to explain it in detail. But, working with technologies like RabbitMQ would expose you to such terminologies.
Service Discovery#
Service discovery is essential part of microservices. Each host on the cluster needs to be known by every other host. If we go by the Wikipedia definition of service discovery, Service discovery is the automatic detection of devices and services offered by these devices on a computer network.
The distributed characteristics of microservices architectures not only make it harder for services to communicate, but also presents other challenges, such as checking the health of those systems and announcing when new applications become available. You also must decide how and where to store meta-store information, such as configuration data, that can be used by applications.
If we talk about software packages which can manage service discovery for us then we have server software like Traefik, Netflix Eureka, HashiCorp Consul.
Chatiness#
By breaking monolithic applications into small microservices, the communication overhead increases because microservices have to talk to each other. In many implementations, REST over HTTP is used because it is a lightweight communication protocol but high message volumes can cause issues.
Caching#
Caches are a great way to reduce latency and chattiness of microservices architectures. Several caching layers are possible, depending on the actual use case and bottlenecks. Many microservice applications running on AWS use Amazon ElastiCache to reduce the volume of calls to other microservices by caching results locally. API Gateway provides a built-in caching layer to reduce the load on the backend servers. In addition, caching is also useful to reduce load from the data persistence layer. The challenge for any caching mechanism is to find the right balance between a good cache hit rate and the timeliness/consistency of data.
Further readings#
- The Twelve-Factor App
- Proxy
- Reverse Proxy
- Load Balancer
- https://en.wikipedia.org/wiki/Producer%E2%80%93consumer_problem
- https://refactoring.guru/design-patterns/facade
If you liked this post, please share it on social media and don’t forget to subscribe below.